Flexible String Matching
This example of data-driven matching was adapted from Flexible String Matching Against Large Databases in Practice.
# general hospital information from CMS
cms.hospitals <- fread("https://data.medicare.gov/api/views/xubh-q36u/rows.csv?accessType=DOWNLOAD") %>%
rename(ProviderID = `Provider ID`,
Name = `Hospital Name`) %>%
mutate_if(is.character, list(~na_if(., "Not Available"))) %>%
mutate_if(is.character, list(~na_if(., ""))) %>%
mutate(Zip = ifelse(nchar(`ZIP Code`) == 5,
as.character(`ZIP Code`),
paste0("0", as.character(`ZIP Code`))),
Phone = str_remove_all(`Phone Number`, "[^0-9]"))
# list of hospitals from homeland security
dhs.hospitals <- fread(paste0("https://opendata.arcgis.com/datasets/",
"a2817bf9632a43f5ad1c6b0c153b0fab_0.csv?",
"outSR=%7B%22latestWkid%22%3A4326%2C%22wkid%22%3A4326%7D"))
# standardize column names
dhs.hospitals <- dhs.hospitals %>%
`colnames<-`(str_to_title(colnames(dhs.hospitals))) %>%
mutate_if(is.character, list(~na_if(., "NOT AVAILABLE"))) %>%
mutate_if(is.numeric, list(~na_if(., -999))) %>%
mutate(Zip = ifelse(nchar(Zip) == 5,
as.character(Zip),
paste0("0", as.character(Zip))),
Phone = str_remove_all(Telephone, "[^0-9]"))
# phone matches for validation
phones <- cms.hospitals %>%
filter(!is.na(Phone)) %>%
select(ProviderID, Phone) %>%
inner_join(dhs.hospitals %>%
select(Id, Phone)) %>%
group_by(ProviderID) %>%
summarise(Matches = n(),
MatchIDs = paste(Id, collapse = "_")) %>%
ungroup() %>%
mutate(MatchIDs = paste0("_", MatchIDs, "_"))
# shared columns
shared.columns <- intersect(colnames(cms.hospitals),
colnames(dhs.hospitals))Objective
Append number of beds to the 4,772 hospitals in Medicare’s general hospital information file by matching with the 6,920 hospital dataset from the Department of Homeland Security.
# stack both lists
combined <- dhs.hospitals %>%
select(Id, Name, Address, City, State, Zip) %>%
mutate(Source = "DHS") %>%
bind_rows(cms.hospitals %>%
select(Id = ProviderID, Name, Address, City, State, Zip) %>%
mutate(Source = "CMS"))
# find exact matches by name, address, city, state and zip
match.exact <- combined %>%
group_by(Name, Address, City, State, Zip) %>%
summarise(n = n_distinct(Id)) %>%
filter(n == 2) %>%
ungroup() %>%
left_join(combined %>%
filter(Source == "DHS") %>%
select(Id, Name, Address, City, State, Zip)) %>%
left_join(combined %>%
filter(Source == "CMS") %>%
select(ProviderID = Id, Name, Address, City, State, Zip))
# standardize remaining records
# drop possesive from Name
# standardize address tokens
# standardize city names
combined.standard <- combined %>%
filter(!Id %in% c(match.exact$Id, match.exact$ProviderID)) %>%
mutate(Name = str_remove_all(Name, "\\'")) %>%
tidytext::unnest_tokens(word, City) %>%
mutate(word = ifelse(word == "st", "saint", word)) %>%
left_join(postal.standards, by = c("word" = "address.token")) %>%
mutate(address.standard = ifelse(is.na(address.standard), word, address.standard)) %>%
group_by(Id, Name, Address, State, Zip, Source)%>%
summarize(City = paste(address.standard, collapse = " ")) %>%
ungroup() %>%
tidytext::unnest_tokens(word, Address) %>%
left_join(postal.standards, by = c("word" = "address.token")) %>%
mutate(address.standard = ifelse(is.na(address.standard), word, address.standard)) %>%
group_by(Id, Name, City, State, Zip, Source) %>%
summarize(Address = paste(address.standard, collapse = " ")) %>%
ungroup()
# find matches after standardization
match.standardize <- combined.standard %>%
group_by(Name, Address, City, State, Zip) %>%
summarise(n = n_distinct(Id)) %>%
filter(n == 2) %>%
ungroup() %>%
left_join(combined.standard %>%
filter(Source == "DHS") %>%
select(Id, Name, Address, City, State, Zip)) %>%
left_join(combined.standard %>%
filter(Source == "CMS") %>%
select(ProviderID = Id, Name, Address, City, State, Zip))
# combine easy matches
match <- match.exact %>%
select(Id, ProviderID) %>%
mutate(group = "Exact",
weight = 1) %>%
bind_rows(match.standardize %>%
select(Id, ProviderID) %>%
mutate(group = "Standardized",
weight = 1))
# unmatched from cms
cms <- cms.hospitals %>%
filter(!ProviderID %in% match$ProviderID)
# unmatched from dhs
dhs <- dhs.hospitals %>%
filter(!Id %in% match$Id)
# name tokens
name.tokens <- cms %>%
tidytext::unnest_tokens(word, Name) %>%
mutate(chr = nchar(word)) %>%
count(word, chr) %>%
ungroup() %>%
mutate(freq = n / sum(n),
share = n / length(unique(cms$Name)))Matching
Both datasets include name, address, city, state, zip and phone. Name, address, city, state and zip will be used for matching. Phone will be reserved for validation.
1,763 records were exact matches. An additional 694 matched after US Postal guidelines were used to standardize the name, address and city, leaving 49% (2,315) of the records unmatched.
Flexible String Matching
- The matching attribute is tokenized into individual words.
- Each token is weighted based on term frequency and inverse document frequency in the target data set.
- The weights are applied to the attribute tokens from the search data set.
- The attribute tokens are matched.
- The combined match weight is calculated and normalized for each pair of matching records.
This alleviates the primary issue with fuzzy string matching, unimportant words obscuring matches.
The non-matching strings ‘4930 LINDELL BOULEVARD’ and ‘4867 SUNSET BOULEVARD’ have a similarity of 0.64 but the similarity of the matching strings ‘Regina Hospital’ and ‘Regina Medical Center’ is only 0.43.
# calculate l2 norm of attribute ----
euc_norm <- function(x){
x1 <- as.matrix(x)
out <- norm(x1, "f")
}
# create dynamic weight from l2 norm of two attributes ----
dynamic_weight <- function(x, y){
out <- sqrt(sum((x^2) + (y^2)))
}
start.clock <- proc.time()
# prepare for matching ----
# calculate term frequency and inverse document frequency from
# match table name & address
# compute dynamic weight
# number of unique values by attribute
# number of unique names & addresses
Base.size <-
as_tibble(
list(
"size.name" =
length(unique(cms$Name)),
"size.address" =
length(unique(cms$Address)))
)
# prep target -----
# split name into tokens
# one token per row
# count token appearance per record id
# count record ids per token
# log of total names/records per token is inverse doc freq
Base.idf.name <- cms %>%
select(tid = ProviderID,
Name) %>%
tidytext::unnest_tokens(word, Name) %>%
filter(!is.na(word)) %>%
select(tid, token = word) %>%
group_by(tid, token) %>%
summarise(term.freq = n()) %>%
group_by(token) %>%
mutate(doc.freq = n_distinct(tid),
idf = log((Base.size$size.name)/(doc.freq))) %>%
ungroup() %>%
mutate(weights = term.freq * idf) %>%
select(tid, token, term.freq, idf, weights)
# repeat for address
# standardize address tokens
Base.idf.add <- cms %>%
select(tid = ProviderID,
Address) %>%
tidytext::unnest_tokens(word, Address) %>%
filter(!is.na(word)) %>%
left_join(postal.standards, by = c("word" = "address.token")) %>%
mutate(token = ifelse(is.na(address.standard), word, address.standard)) %>%
select(tid, token) %>%
group_by(tid, token) %>%
summarise(term.freq = n()) %>%
group_by(token) %>%
mutate(doc.freq = n_distinct(tid),
idf = log((Base.size$size.address)/(doc.freq))) %>%
ungroup() %>%
mutate(weights = term.freq * idf) %>%
select(tid, token, term.freq, idf, weights)
# compute total weight for each record's name & address
# then dynamic weight
Base.length <- Base.idf.name %>%
select(tid, weights) %>%
nest(-tid) %>%
mutate(l.x = map_dbl(data, euc_norm)) %>%
select(tid, l.x) %>%
full_join(Base.idf.add %>%
select(tid, weights) %>%
nest(-tid) %>%
mutate(l.y = map_dbl(data, euc_norm)) %>%
select(tid, l.y)) %>%
mutate_if(is.numeric, replace_na, 0) %>%
group_by(tid) %>%
mutate(len = map2_dbl(l.x, l.y, dynamic_weight)) %>%
ungroup() %>%
select(tid, l.x, l.y, len)
# weight by name token
idf.name <- Base.idf.name %>%
select(token, idf) %>%
unique() %>%
arrange(idf, token)
# weight by address token
idf.address <- Base.idf.add %>%
select(token, idf) %>%
unique() %>%
arrange(idf, token)Inverse Document Frequency
Using inverse document frequency increases the value of rare words and decreases the value of common words. A match including Regina is 3 times as important as a match including both ‘Medical’ and ‘Center’.
idf.name %>%
head(5) %>%
bind_rows(idf.name %>%
filter(token == "regina")) %>%
mutate(group = "Name") %>%
bind_rows(idf.address %>%
head(4) %>%
bind_rows(idf.address %>%
tail(1)) %>%
bind_rows(idf.address %>%
filter(token == "blvd")) %>%
mutate(group = "Address")) %>%
ggplot(aes(fct_reorder(token, idf), idf))+
geom_col(aes(fill = idf),
show.legend = F)+
labs(title = "Weights of unique and frequent tokens",
subtitle = paste("There are",
comma(nrow(filter(idf.name, idf == max(idf)))),
"unique name and",
comma(nrow(filter(idf.address, idf == max(idf)))),
"unique address tokens"),
x = NULL,
y = "Match Weight")+
facet_grid(rows = vars(group), scales = "free")+
coord_flip()+
theme(strip.background = element_rect(fill = "white",
colour = "grey50"),
strip.text.y = element_text(angle = 0,
face = "bold"),
panel.background = element_rect(fill = "white",
colour = "grey50"),
axis.text = element_text(size = rel(1)))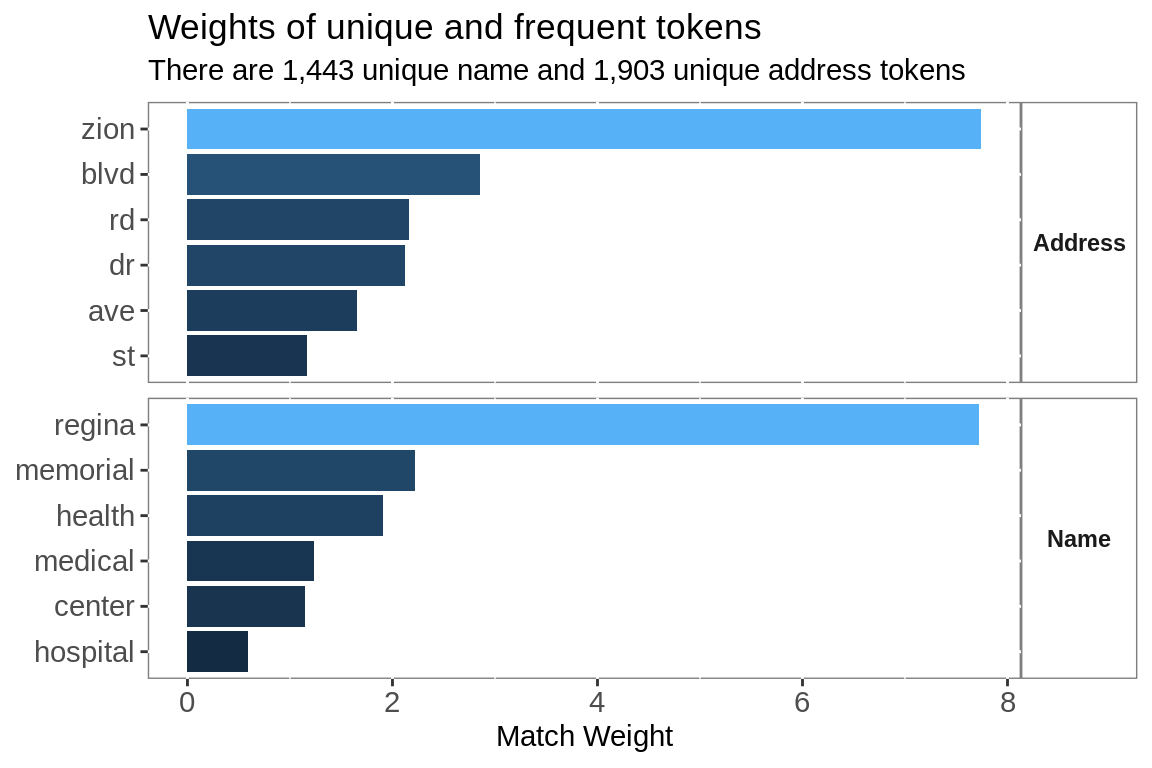
In a similar manner, the match weights of multiple attributes can be weighted dynamically, increasing the value of rare name matches over common address matches or vice versa.
# normalize name weights
Base.weights.name <- Base.idf.name %>%
inner_join(Base.length, by = "tid") %>%
mutate(t.weight = weights/l.x,
t.weight.dyn = weights/len) %>%
select(tid, token, t.weight.dyn)
# normalize address weights
Base.weights.add <- Base.idf.add %>%
inner_join(Base.length, by = "tid") %>%
mutate(t.weight = weights/l.y,
t.weight.dyn = weights/len) %>%
select(tid, token, t.weight.dyn)
# update to data.tables
setDT(Base.weights.name)
setDT(Base.weights.add)
# prep source ----
# apply weighting to matching name
# split by tokens and count
# use idf from match table
Search.idf.name <- dhs %>%
select(sid = Id,
Name) %>%
tidytext::unnest_tokens(word, Name) %>%
filter(!is.na(word)) %>%
select(sid, token = word) %>%
group_by(sid, token) %>%
summarise(term.freq = n()) %>%
ungroup() %>%
inner_join(idf.name) %>%
mutate(weights = term.freq * idf) %>%
select(sid, token, weights)
# apply weighting to matching address
Search.idf.add <- dhs %>%
select(sid = Id,
Address) %>%
tidytext::unnest_tokens(word, Address) %>%
filter(!is.na(word)) %>%
left_join(postal.standards, by = c("word" = "address.token")) %>%
mutate(token = ifelse(is.na(address.standard), word, address.standard)) %>%
select(sid, token) %>%
group_by(sid, token) %>%
summarise(term.freq = n()) %>%
ungroup() %>%
inner_join(idf.address) %>%
mutate(weights = term.freq * idf) %>%
select(sid, token, weights)
# compute total weight for each record's name & address
# then dynamic weight
Search.length <- Search.idf.name %>%
select(sid, weights) %>%
nest(-sid) %>%
mutate(l.x = map_dbl(data, euc_norm)) %>%
select(sid, l.x) %>%
full_join(Search.idf.add %>%
select(sid, weights) %>%
nest(-sid) %>%
mutate(l.y = map_dbl(data, euc_norm)) %>%
select(sid, l.y)) %>%
mutate_if(is.numeric, replace_na, 0) %>%
group_by(sid) %>%
mutate(len = map2_dbl(l.x, l.y, dynamic_weight)) %>%
ungroup() %>%
select(sid, l.x, l.y, len)
# normalize name weights
Search.weights.name <- Search.idf.name %>%
inner_join(Search.length, by = "sid") %>%
mutate(s.weight = weights/l.x,
s.weight.dyn = weights/len) %>%
select(sid, token, s.weight.dyn)
# normalize address weights
Search.weights.add <- Search.idf.add %>%
inner_join(Search.length, by = "sid") %>%
mutate(s.weight = weights/l.y,
s.weight.dyn = weights/len) %>%
select(sid, token, s.weight.dyn)
# update to data.tables
setDT(Search.weights.name)
setDT(Search.weights.add)
# exclude matches below
threshold <- 0.3
# match name tokens
match.name <-
Base.weights.name[Search.weights.name,
on = "token",
allow.cartesian = T
][,
.(weight.x.dyn =
sum(t.weight.dyn *
s.weight.dyn)),
by = c("tid",
"sid")
][weight.x.dyn >= threshold]
# fix columns
setnames(match.name,
c("tid", "sid"),
c("ProviderID", "Id"))
# set keys
setkeyv(match.name, cols = c("ProviderID", "Id"))
# match address tokens
match.add <-
Base.weights.add[Search.weights.add,
on = "token",
allow.cartesian = T
][,
.(weight.y.dyn =
sum(t.weight.dyn *
s.weight.dyn)),
by = c("tid",
"sid")
][weight.y.dyn >= threshold]
# fix columns
setnames(match.add,
c("tid", "sid"),
c("ProviderID", "Id"))
# set keys
setkeyv(match.add, cols = c("ProviderID", "Id"))
# combine matches
match.weight <- merge(match.add, match.name, all = TRUE)
# add secondary attributes, city, state, zip
# calculate secondary matches
match.weight <- match.weight %>%
mutate(weight.x.dyn = ifelse(is.na(weight.x.dyn), 0,
weight.x.dyn),
weight.y.dyn = ifelse(is.na(weight.y.dyn), 0,
weight.y.dyn),
match.weight.dyn = weight.x.dyn + weight.y.dyn) %>%
select(ProviderID,
Id,
match.weight.dyn) %>%
left_join(cms %>%
select(ProviderID,
Name,
City,
State,
Zip) %>%
tidytext::unnest_tokens(word, City) %>%
mutate(word = ifelse(word == "st", "saint", word)) %>%
left_join(postal.standards, by = c("word" = "address.token")) %>%
mutate(address.standard = ifelse(is.na(address.standard), word, address.standard)) %>%
group_by(ProviderID, Name, State, Zip)%>%
summarize(City = paste(address.standard, collapse = " "))) %>%
left_join(dhs %>%
select(Id,
Name,
City,
State,
Zip) %>%
tidytext::unnest_tokens(word, City) %>%
mutate(word = ifelse(word == "st", "saint", word)) %>%
left_join(postal.standards, by = c("word" = "address.token")) %>%
mutate(address.standard = ifelse(is.na(address.standard), word, address.standard)) %>%
group_by(Id, Name, State, Zip)%>%
summarize(City = paste(address.standard, collapse = " ")), by = "Id") %>%
mutate(City = City.x == City.y,
Zip = Zip.x == Zip.y,
Zip3 = str_sub(Zip.x, 1, 3) == str_sub(Zip.y, 1, 3),
secondary.weight = (City + Zip + Zip3) / 3,
weight = (match.weight.dyn + secondary.weight) / 2)
# eliminate matches across state lines
# rank search matches
matched <- match.weight %>%
filter(State.x == State.y) %>%
group_by(ProviderID) %>%
mutate(rank.id = dense_rank(desc(weight))) %>%
ungroup()
# potential matches per record
matched.per <- match.weight %>%
mutate(group = "All Potential Matches") %>%
bind_rows(matched %>%
mutate(group = "After State Filter")) %>%
group_by(ProviderID, group) %>%
summarise(n = n(),
gap = max(weight) - min(weight),
match.weight.dyn = mean(match.weight.dyn),
weight = mean(weight)) %>%
mutate(n = case_when(n > 4 ~ "5+",
TRUE ~ as.character(n)),
n = factor(n, levels = c("1",
"2",
"3",
"4",
"5+"))) %>%
group_by(n, group) %>%
summarize(hospitals = n_distinct(ProviderID),
match.weight.dyn = mean(match.weight.dyn),
weight = mean(weight),
gap = mean(gap))
# select best match by target record
matched.final <- matched %>%
filter(secondary.weight == 1 |
match.weight.dyn == 1 |
weight > 0.531) %>%
group_by(ProviderID) %>%
arrange(desc(weight), desc(match.weight.dyn), .by_group = T) %>%
filter(row_number() == 1) %>%
ungroup()
match.time <- proc.time() - start.clockPotential Matches
The downside to matching by word, is a high volume of potential matches, in this case 4 potential matches per record.
Spurious matches are eliminated using the remaining attributes; state, city and zip.
Eliminating matches not in the same state reduces the number of potential matches per record to 2.
ggplot(matched.per, aes(n, hospitals, group = group))+
geom_col(aes(fill = fct_rev(group)),
position = "dodge")+
geom_text(aes(label = comma(hospitals)),
position = position_dodge(width = 0.9),
color = "white",
fontface = "bold",
vjust = 1.25,
size = 3)+
labs(title = "Potential matches per record",
subtitle = paste0("State filter eliminates ",
round(nrow(matched)/nrow(cms))/round(nrow(match.weight)/nrow(cms)) * 100,
"% of potential matches"),
x = NULL,
y = NULL)+
scale_y_continuous(labels = scales::comma)+
scale_fill_brewer(palette = "Set1")+
guides(fill = guide_legend(title = NULL, reverse = T))+
theme(panel.background = element_rect(fill = "white",
colour = "grey50"),
axis.text = element_text(size = rel(1)))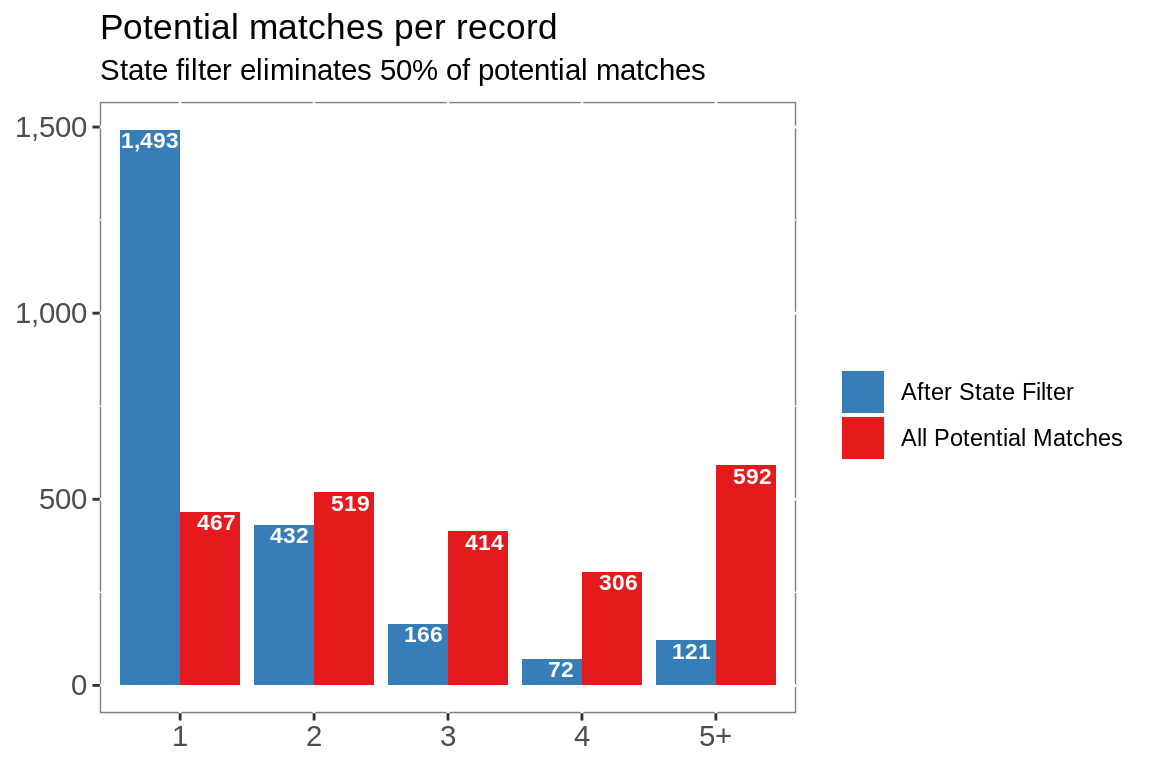
The best match per Provider ID is selected by combining the match weight with weights for city and zip matches.
97% of records were matched.
160 records were matched per second, with 2,315 records matched against 5,113 in 14.454 seconds
# combine flexible and easy matches
# check against phone matches
match.all <- match %>%
bind_rows(matched.final %>%
select(Id, ProviderID, weight) %>%
mutate(group = "Flexible")) %>%
left_join(cms.hospitals %>%
select(ProviderID, Name, State, `Hospital Type`:`Hospital overall rating`,
ends_with("comparison"))) %>%
left_join(dhs.hospitals %>%
select(Id, Type:Helipad)) %>%
left_join(phones) %>%
mutate(group = factor(group, levels = c("Flexible",
"Exact",
"Standardized")),
`Phone Match` = str_detect(MatchIDs, paste0("_", Id, "_")),
`Phone Match` = case_when(is.na(`Phone Match`) ~ "Not Reported",
`Phone Match` == T ~ "Match",
`Phone Match` == F ~ "No Match"),
`Phone Match` = factor(`Phone Match`, levels = c("No Match",
"Match",
"Not Reported"))) %>%
select(-Country, -Matches, -Ttl_staff, -St_fips, -Sourcedate, -Val_date)
# match weights
matched.final %>%
ggplot(aes(weight))+
geom_histogram(bins = 40,
fill = "#377EB8")+
labs(title =
paste0(round(nrow(filter(matched.final, weight == 1))/
nrow(matched.final),2)*100,
"% were exact matches"),
x = "Match Weight",
y = "Records")+
theme(panel.background = element_rect(fill = "white",
colour = "grey50"),
axis.text = element_text(size = rel(1.2)))
# phone matches
match.all %>%
group_by(group, `Phone Match`) %>%
summarise(n = n()) %>%
group_by(group) %>%
mutate(percent = n / sum(n)) %>%
ggplot(aes(group, n, fill = `Phone Match`))+
geom_col(position = "fill")+
guides(fill = guide_legend(title = "Phone Match"))+
scale_y_continuous(labels = scales::percent)+
labs(title = "Phone validation by match type",
x = NULL,
y = "Matches")+
theme(panel.background = element_rect(fill = "white",
colour = "grey50"),
axis.text = element_text(size = rel(1.2)))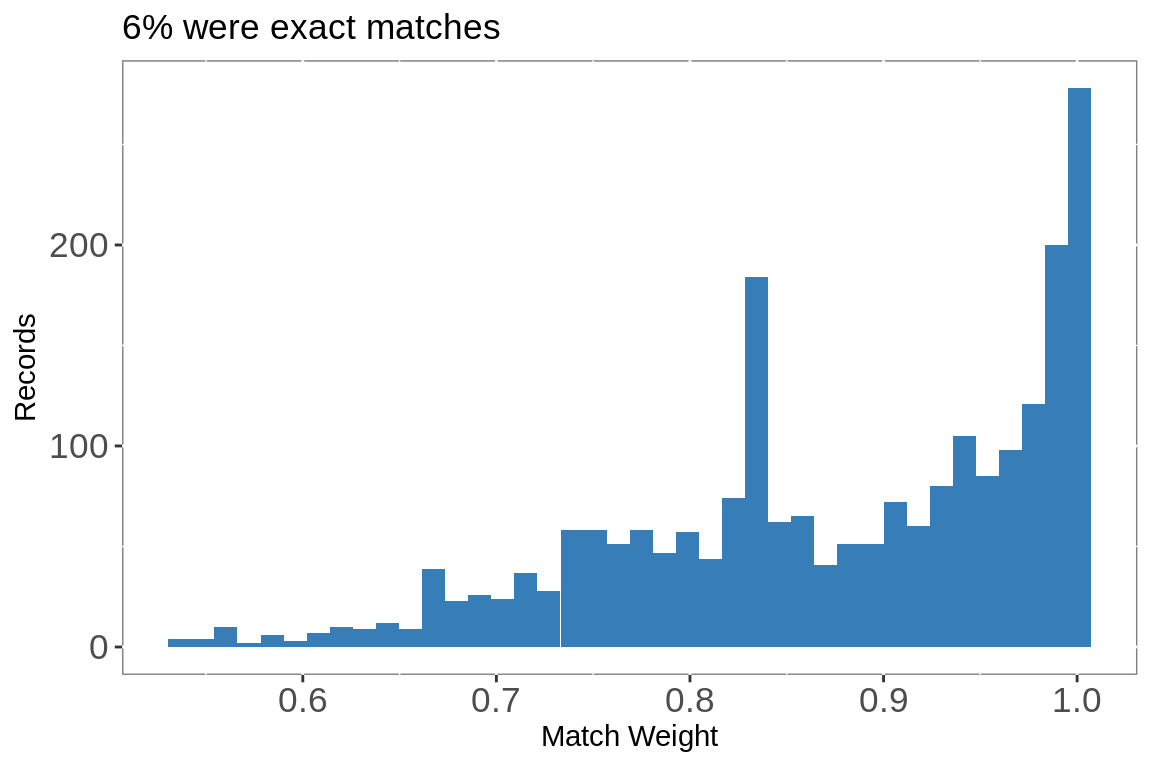
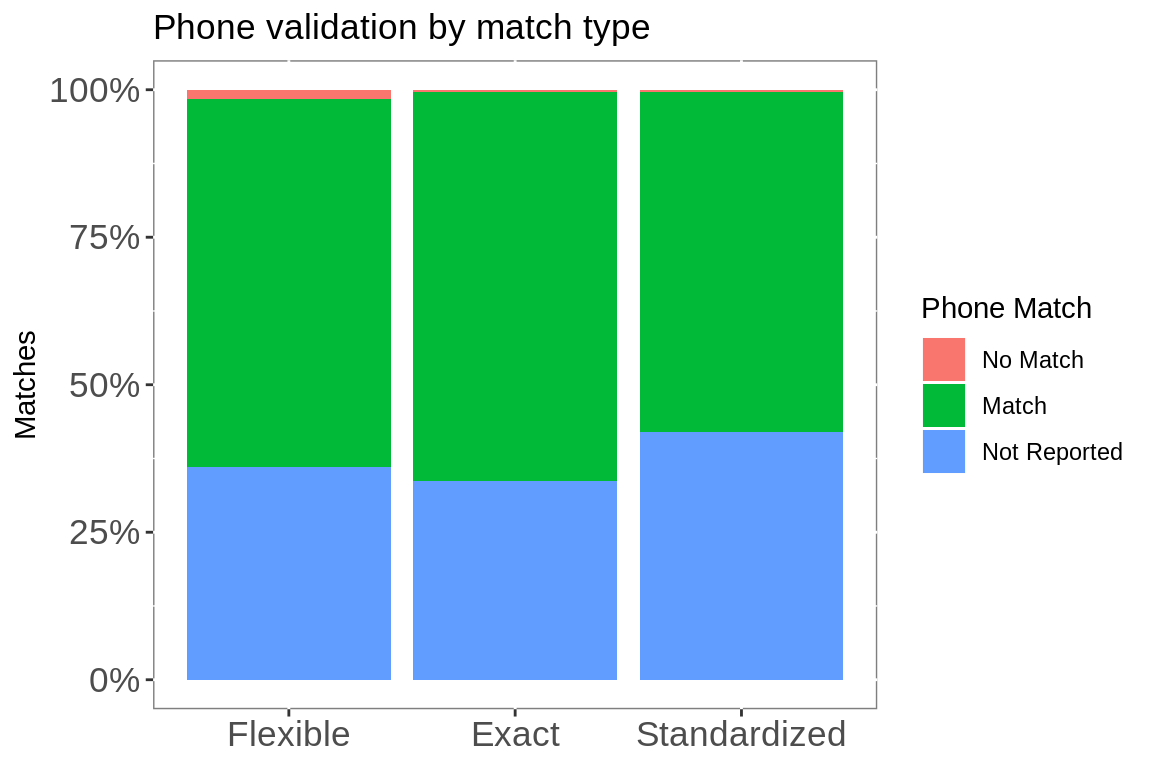
Results
# fix trauma levels
hospitals <- match.all %>%
filter(Status == "OPEN") %>%
mutate(`Hospital overall rating` = factor(`Hospital overall rating`,
levels = c("1",
"2",
"3",
"4",
"5"))) %>%
trauma_levels()
# rating by beds
rating <- hospitals %>%
filter(!is.na(`Hospital overall rating`) &
!is.na(Beds))
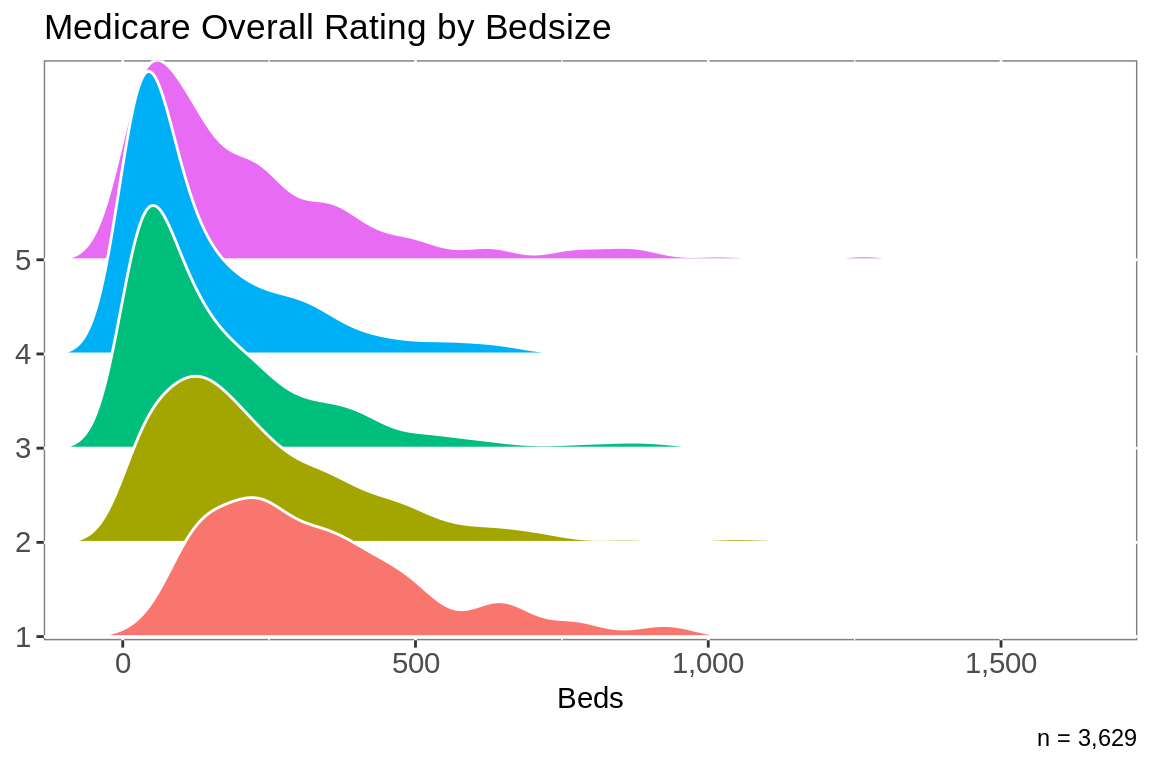
rating %>%
ggplot(aes(y = `Hospital overall rating`, x = Beds, fill = `Hospital overall rating`)) +
geom_density_ridges2(scale = 3,
show.legend = F,
color = "white") +
scale_y_discrete(expand = c(0.01, 0)) +
scale_x_continuous(expand = c(0.01, 0),
labels = scales::comma)+
labs(title = "Medicare Overall Rating by Bedsize",
x = "Beds",
y = NULL,
caption = paste("n =",
comma(nrow(rating))))+
theme(panel.background = element_rect(fill = "white",
colour = "grey50"),
axis.text = element_text(size = rel(1)))